第二章 在一张表上的单条件查询
如果一个数据库有着良好的设计,数据都应该保存在不同的表中。正如我们的高尔夫数据库就把会员、队伍、比赛分别保存在了不同的表中,并将它们的数据都关联在了一起。比如哪些会员加入了哪些队伍,参加过哪些比赛,以及其它。为了以最好的方式利用我们的数据,我们需要在不同的表中检查数据确认哪些是我们所要的。
在这一章中,我们将会关注从单表中获取数据。这可能是数据库中的一张永久表(permanent table),也可能是用以临时储存复杂查询结果集的一部分的虚拟表(virtual table)。
我对“检索”和“返回”的讲述一直都不太准确。查询出结果对行来说发生了什么?事实上,我们并没有从表中删除数据或者将其放在哪里。查询就像是数据库对外的一个窗口,通过这个窗口可以看到我们想要的信息。如果数据库底层的数据有了改变,查询出的结果也会改变。只要你能理解这只是临时的,就并不难理解查询将“搜索”到的数据存放在“虚拟表”中。
行和列(字段)注0的子集
在查询的时候选择行或者列的子集是一个非常惯用的手法。下文我们将关注从数据库的一张表中选择一些行和列注1。通过其他方式从虚拟表中获得数据的方式也一样有效。
在决定要从表里面获取哪一行之前,必须要通过一个是否判断语句来表示检索条件。我们把条件作用在独立的表的每一行上,保留判断为真的条件并舍弃其它。所以当我们说要去找高尔夫俱乐部中的所有高级会员(senior member)时,我们仅仅需要的是 Member 表中 MemberType 字段的值是“Senior”的那些行的子集,就像 图2-1 所示。
图2-1 获取高级会员的行的子集

查找高级会员的 SQL 语句就像下面这样:
SELECT *
FROM Member
WHERE MemberType = 'Senior'
这条 SQL 有三个部分,或者说子句:SELECT 子句告诉了我们要找哪些字段。在这个例子中*的意思是查找所有的字段。FROM 子句告诉我们需要去查找那张(些)表,还有 WHERE 子句决定了只有符合特定条件的行会被选中到结果中。这里的条件是要检查 MembetType 域中的值。在 SQL 中,当我们给一个文本字段或者字符字段,我们需要给值的两边包裹上单引号,就像'Senior' 这样。
现在让我们看看数据库是怎么从表中找到那些我们想要的某些列的。通常我指的是选择出行的子集以及映射(project)出列的子集。映射一个列的子集通常是一系列操作的最后一步。我们可以这样认为:先把我们要的所有数据都收集起来,然后最后再去检出哪些我们想要的属性或者字段。我们将会在 第7章 中看到有些时候我们也会在引用某些集合操作前从原始(original)或者虚拟( virtual )表中中去映射相似的字段,比如 union 和 intersect 。
如果我们仅仅想要一个所有会员电话号码的列表,而不要其他诸如差点和加入日期的信息。图2-2 展示了 Member 表的 mane 和 phone number 字段的子集。
图2-2 映射必须要有电耗号码列的子集
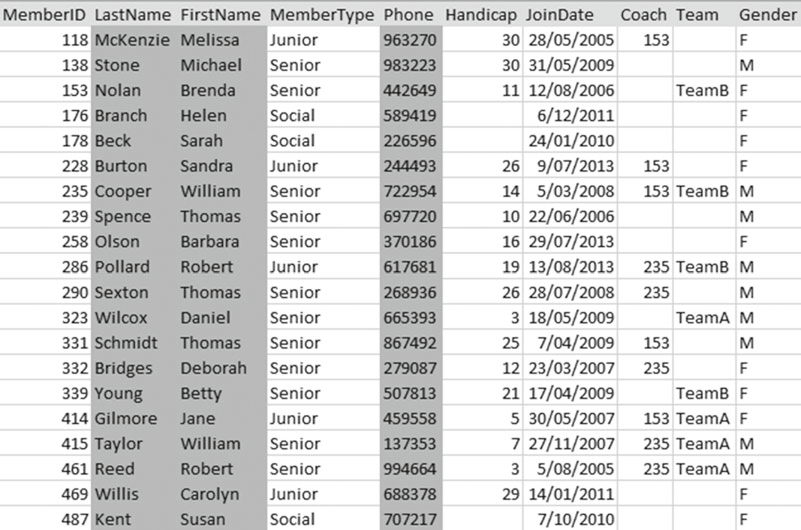
从 Member 表中查找名字和电话号码的字段的 SQL 是这样的:
SELECT LastName, FirstName, Phone
FROM Member
因为我们要看到所有行的些字段的值,所以这次查询没有 WHERE 子句。
把行和列的检索结果组合成一个子集是一个非常简单的事情。如果我们仅仅想要得到高级会员的的电话列表,就像 图2-3 那样。
图2-3 查找出的高级会员的电话列表的行和列子集
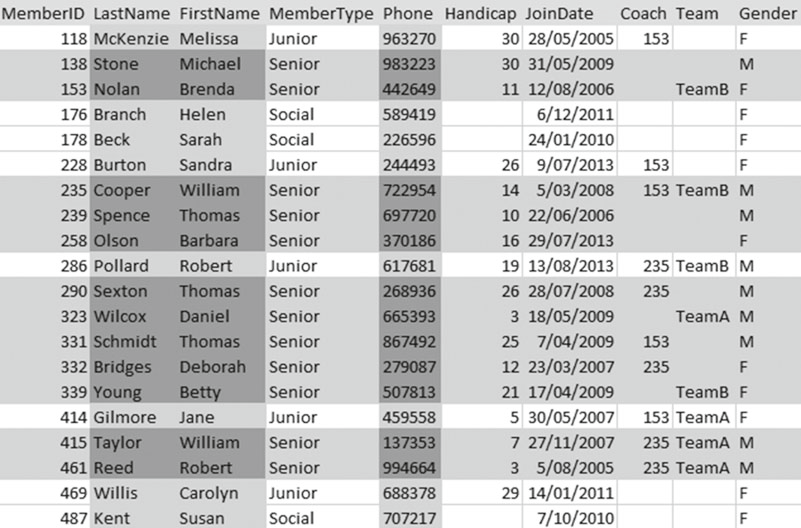
图2-3 中的 SQL 是这么写的:
SELECT LastName, FirstName, Phone
FROM Member
WHERE MemberType = 'Senior'
使用别名(alias)
当我们将不同的表组合在一起时候,我们的查询会变得越来越复杂。有些表或许会有一些同名的字段,这时候我们就需要去区分它们。在 SQL 中我们可以在查询中每个属性前面加上表名来表示这个字段来自哪张表。就像这样:
SELECT Member.LastName, Member.FirstName, Member.Phone
FROM Member
WHERE Member.MemberType = 'Senior'
因为输入完整的表名会比较麻烦,另外我们也在一些查询中去比较来自一张表的许多行的数据,所以 SQL 有了一个别名的概念。我们看一下下面这个查询:
SELECT m.LastName, m.FirstName, m.Phone
FROM Member m
WHERE m.MemberType = 'Senior'
在这里的 FROM 子句中,我们给 Member 表起了一个叫 m 的别名或者叫替代名。我们可以给别名起任何我们喜欢的名字,只要简单就好。然后在查询剩下的部分中我们可以使用这个别名去定位Member 里的任意属性。给每张表都起一个别名是一个好习惯。
保存查询
有些时候会需要将查询的结果放在一张新的永久表中(有些时候也叫它快照(snapshot)),因为一旦底层数据有所改变,这些快照就会过时,所以我们通常并不希望这么去做。我们最想要的是保存查询指令(query instructions),以便于我们可以在其他时候执行相同的命令。想一想我们的电话表查询,在俱乐部的会员列表更新后,我们都会重新生成电话表。而不是每次都要重新写查询,我们可以把储存起来的指令称为视图(view)。下面的代码展示了怎么去创建一个视图,我们可以通过这个视图来获得最新的电话表。我们必须要给这个视图起一个任意我们喜欢的名字(PhoneList 看起来不错),然后绑定 SQL 语句就可以得到我们想要的数据了。
CREATE VIEW PhoneList AS
SELECT m.LastName, m.FirstName, m.Phone
FROM Member m
你可以认为 PhoneList 是通过指令创建的一张“虚拟”表,所以我们在用其他真实的表进行查询的时候也用同样的方式来处理。我们只要知道虚拟表是在永久的 Member 表上执行查询语句动态创建的就可以了。这下我们就可以通过 PhoneList 视图非常简单地获得电话表了。
SELECT * FROM PhoneList
指定筛选行的条件
在前面章节的查询中我们可以看到,我们需要使用通过的条件或者标准来决定哪些行可以被筛选到查询的结果中。在下面的章节中,我们会看到更细致地研究通过不同方法来实现指定的复杂条件。
比较运算符(Comparison Operators)
提交是一个值为真或假的语句或者表达式,就像 MemberType = 'Senior' 。这种类型的表达式被称为布尔表达式注2,以研究了布尔表达式的19世纪英国数学家乔治·布尔命名。这些条件是我们用来从表中筛选数据的,常常需要去将一个属性的值和某些常量(constant)或者另一个属性去比较。比如我们可以要求属性的值是否相等、不等、或者大于其他值。表2-1 展示了一些我们会在查询中用到的比较运算符。
表2-1 比较运算符
| 运算符 | 释义 | 示例 |
|---|---|---|
| = | 等于 | 5=5 , 'Junior' = 'Junior' |
| < | 小于 | 4<5 , 'Ann' < 'Zebedee' |
| <= | 小于等于 | 4<=5 , 5<=5 |
| > | 大于 | 5>4 , 'Zebedee' > 'Ann' |
| >= | 大于等于 | 5>=4 , 5>=5 |
| <> | 不等于 | 5<>4 , 'Junior' <> 'Senior' |
只是一个简短的提醒:在 表2-1 的例子中我们示意了数字和一些字符(character)的比较。我们重新去看 第1章 创建一张表,我们为每个字段都指定了一个类型,比如 MemberID 被指定为 INT (整数),还有 LastName 是 CHAR(20) (20个字符的空间)。对于整数这样的字段,可以直接比较值。比较文本(text)或者字符字段,则通过字母顺序来比较,还有日期和时间字段则会按时间顺序(哪个时间更早)来比较。
当我们比较字符的时候,会基于 ASCII注3 或者 Unicode注4 的值来进行。就像“A”(ASCII码值65)早于“Z”(ASCII码值90),所以“A”<“Z”。如果是一个字符串,当第一个相等的时候会按顺序接着比较第二个、第三个,直到最后。所以“ANNABEL”<“ANNE”。同时,小写字母也比大写字母拥有更靠后的排序,就像“a”(ASCII码值97)>“Z”(ASCII码值90)。如果按默认的照字母顺序去排序的话,有小写字母的字符串会比有大写字母的单词出现的更晚。比如“van Dyke””会在“Zebedee”之后才出现。
如果我们把数字也当作文字,他们也会遵守字母顺序。这就表示你会得到类似“400”<“5”这样的结果。因为左侧的第一个字符“4”(ASCII码值34)“4”(ASCII码值34)小于右侧的第一个字符“5”(ASCII码值35)。所以一定要弄清楚包含了数字的字段是按照数字顺序来进行比较和排序的,以及这个字段确实是数字类型,不然你只会从查询的中得到一些意想不到的结果。同理,日期字段必须使用日期格式,不然比较和排序的结果可能就不是您所想要的了。
通过比较运算符,我们可以进行更多不同的查询。表2-2 列出了一些我们能将其作用于 SQL语句的 WHERE子句 中的布尔(boolean)表达式,以便 SQL语句 可以从 Member 表中查找想要找的行。
表 2-2 Member表 布尔表达式的例子
| 表达式 | 得到的行 |
|---|---|
| MemberType = 'Junior' | 所有初级(Junior)会员 |
| Handicap <= 12 | 所有差点小于等于12的会员 |
| JoinDate >= '01/01/2008' | 所有在2008年及以后才加入的会员 |
| Gender = 'F' | 所有女性会员 |
有些 SQL 在查询的时候区分大小写,而有些不是。区分大小写也就认为大写字母和小写字母是不一样的。换句话说,“Junior”和“junior”不一样,和“JUNIOR”也都不一样。我经常要随机检查我们的新数据库系统看看它们做了什么。如果你不注意正在输入的内容的大小写(比如,您对在 MemberType 中用“Junior”或者“jUnIoR”或者别的方式的检索结果没什么意见注5)你可以使用 SQL 中的 UPPER 函数。这个函数会在进行比较之前把所有的目标文本都转换成大写字母注6。你就可以让它和大写字母进行对比,就像下面的代码:
SELECT *
FROM Member m
WHERE UPPER(m.MemberType) = 'JUNIOR'
逻辑运算符(Logical Operators)
我们可以把多个布尔表示联合在一起,去创造更有趣的条件。比如,我们可以指定两个表达式在检索特定的行的时候都必须为真(true)。
假设我们要找到所有初级女性会员。这就需要让两个条件为真:必须是女性且必须是初级会员。我们可以很容易地将这两个条件独立表达出来。在这之后我们通过一个 AND 逻辑运算符去将降格条件联合起来:
SELECT *
FROM Member m
WHERE m.MemberType = 'Junior' AND m.Gender = 'F'
我们将会学习三个逻辑运算符:AND(与)、OR(或)以及 NOT(非)。我们已经知道了 AND 是如何工作的了。如果我们在两个表达式之间使用 OR ,就表示只要一个表示为真就可以了(如果两个同时为真也没关系)。NOT 作用于一个表达式。比如要从我们的 Member 表中指定条件 NOT (MemberType = 'Social')。这表示检查所有行,并找到 MemberType 的值是“Social”的行,然后舍弃这些行。表2-3 给出了更多使用逻辑表达式的例子。
表2-3 逻辑表达式示例 | 表达式 | 释义 | | --- | --- | | MemberType = 'Senior' AND Handicap < 12 | 高级会员,且差点小于12 | | MemberType = 'Senior' OR Handicap < 12 | 高级会员,或者差点小于12 | | NOT(MemberType = 'Social') | 除了特别会员注7外的所有会员(当前的数据中只有高级会员和初级会员) |
图2-4 是 表2-3 查询结果的示意图。每个圆都代表了一字段的集合(就像是特别会员或者差点低于12的会员)。阴影部分则是逻辑运算的结果。
图2-4 逻辑运算的示意图
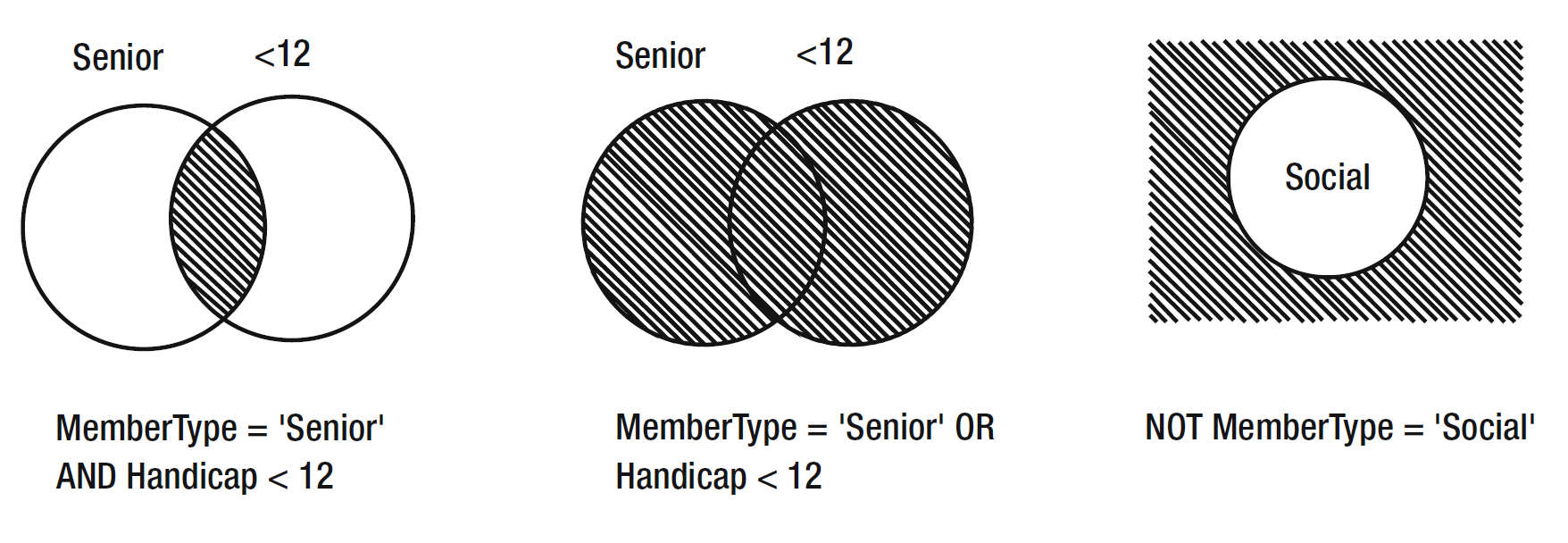
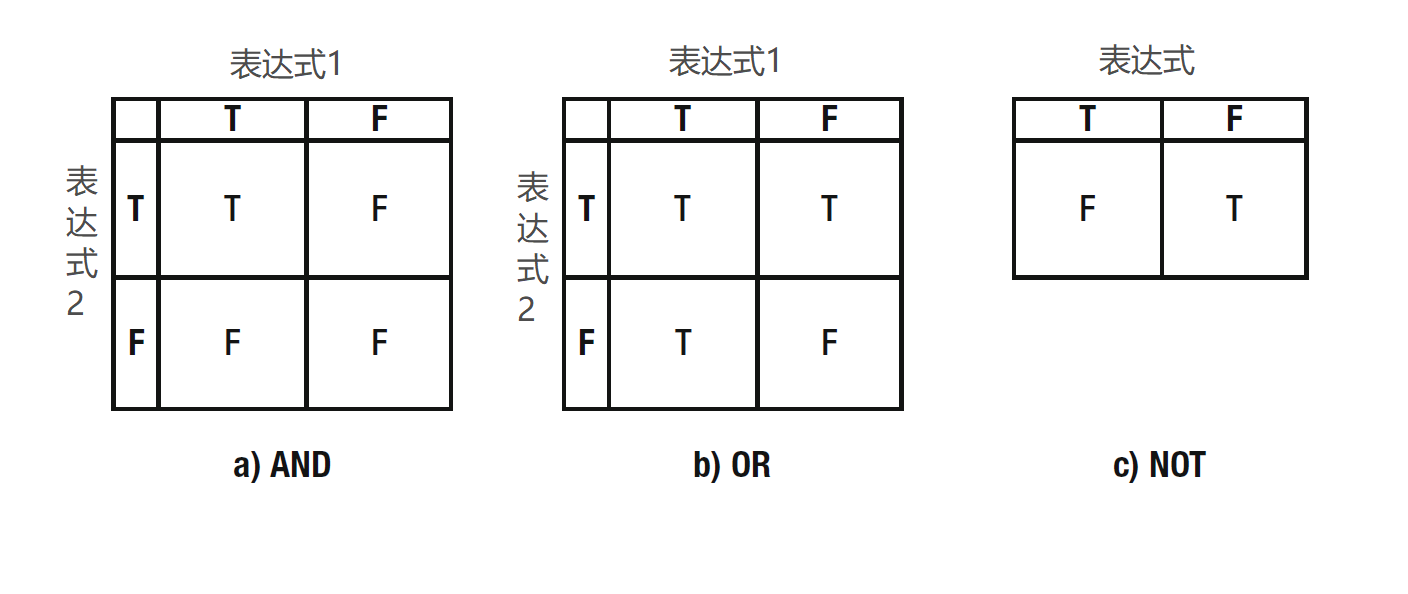
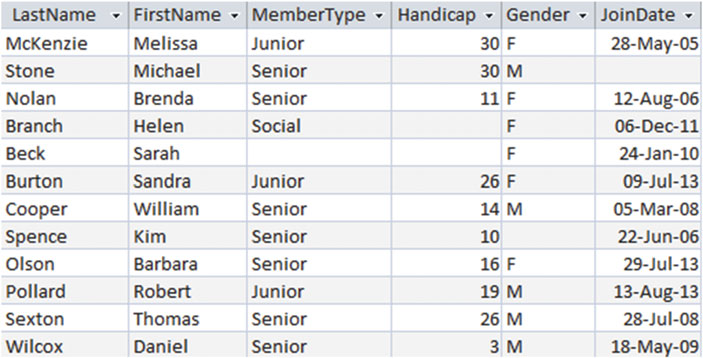
图2-5 的真值表注8可以帮助我们去理解逻辑运算符是怎么工作的。你需要先这样看他们:在图2-5a 和 2-5b 中,我们有两个表达式,一个横在上边,一个竖在左边。每个表达式都有两个值:真(T)或假(F)。如果我们将它们通过“与(AND)”表达式来组合,那 图2-5a 表示只有当所有表达式都为真时结果才为真(表格的左上角)。如果我们将它们通过“或(OR)”表达式来组合,那在所有结果中只有全部是假最终结果才是假(图2-5b的右下角)。图2-5c中的表说明如果原始结果是真,,而我们在其之前放置了非(NOT),那结果也是假(左边的列),反之亦然注9。
图2-5 逻辑运算的真值表(T=真,F=假)
有些时候将自然语言翻译为布尔表达式会有些困难。如果你被要求提供一份包括所欲偶女性会员和初级会员的列表(别问为什么!),你或许会将上述文字翻译成这样的组合 MemberType = 'Junior' AND Gender = 'F'。可惜 AND 表示两个提交都要满足,所以结果只会给出初级女性会员。而我们的自然真正想要的意思是“我想要一个是女性会员或者初级会员(或者两个都是)的结果”。小心再小心。
处理 NULL(空值)
之前在 图2-1 所示里的Member表 里的数据都是准确完整的。每一行的所有属性都有一个所对应的值,但也并非都是如此,就像 Handicap 。真实的数据一般并不会这么干净整齐。让我们关注 图2-6 里所示的另一份数据。
图2-6 包含缺失数据的表
如果表格中的单元格中并没有数据,我们把这个状态称为 null(空) 。null 是数据库经常会让人头疼的东西。思考一下这么两条执行:一条去列出所有男性会员,另一条列出所有女性会员。要知道所有高尔夫选手需要表明自己的性别才能参赛,所以我们俱乐部所有的会员都应该会被列在两张表格的一张中。但是从 图2-6 的数据中我们会看到,我们会丢失 Kim Spence 这名会员。你也许会说不应该让数据变成那样,但我们在讨论的是缺少了准确和完整的数据的真实会员和俱乐部之间的关系。或许 Kim 忘记(或者拒绝)登记性别信息。我们可以通过在创建表的时候不允许出现 null 来规避这个问题。下面的 SQL 就像我们展示了如果让 Gender 字段必须有一个值:
CREATE TABLE Member (
MemberID INT PRIMARY KEY,
.....
Gender CHAR(1) NOT NULL,
....)
需要注意的是,为字段添加非空(NOT NULL)可能会比因为NULL 而导致更多的问题。虽然 Kim Spence 没有完整地填写申请表上的所有内容,但实际上已经支付了会员款,那我们就会先将其记录为会员,之后才会去考虑将信息完整化。如果我们将 Gender 设置为必填字段,那我们就无法创建数据——除非我们去猜测会员的性别是什么。这两种方法都不是最好的选择,所以我们最好允许在创建字段的使用可以留空。要知道我们的主键(根据定义注10)总是会有值的。
并不说所有数据只要有 NULL 就是有问题的。在我们的 Member表 中,一个字段没有值仅仅是因为它并没有指定给某个会员。Helen 和 Sarah 的差点可能真的是 0 ,因为她们都没有参加过比赛注11。但所有成员的 MemberType 和 JointDate 都被要求有一个值,所以这些字段中的 null 值是因为我们不知道这些值是什么。事实上,您无法保证您的表不会丢失数据。
找到 NULL
考虑到在我们的表中有可能发生问题的空值,下面的方法会比较容易帮助我们去找到那些空值。当我们把一批新会员插入数据库后,我们应该去检查错误。我们可以用下面的 SQL 来判断 NULL,并得到一份关于哪些会员没有填写 Gender 值的列表:
SELECT *
FROM Member m
WHERE m.Gender IS NULL
换言之,我们希望得到的是在单元格中填写了值的那些会员。如果我们想要那些在 Handicap 有值的会员姓名和差点值,我们可以使用 NOT 操作符来创建下面的查询:
SELECT *
FROM Member m
WHERE NOT (m.Handicap IS NULL)
关于空值的比较
如果在我们的表中产生了一些不可预料的空值,知道怎么去处理它们就变得很重要了。哪些行会匹配下面两个条件的搜索结果?
Gender = 'F'
NOT (Gender = 'F')
你或许会想,如果我们执行这两个查询,一个是得到所有符合条件的行,一个是得到所有不符合条件的行,那就得到了整张表的内容。但事实上并非如此。Kim 并不符合第一个条件,因为很显然 Kim 的 Gender 值并不是 'F'。但如果我们问为什么不是 'F' 的话,我们却不能说我们不知道这个值是什么。也许这个值就是 F 。在 SQL 中,我们把 NULL 值和其他某个值进行比较的时候,我们不会得到真或者假,因为我们的确不知道。如果我们把这个问题用在差点上,或许会更有意义。当我们要找 Handicap > 12 ,以及 NOT(Handicap > 12) OR Handicap <= 12 的会员的时候,Sarah 可能永远都不会被找到。这个查询不适合他——因为她没有获得过差点。
当把 null 也考虑进去,我们的表达式就会有三个值了:真、假和“不知道”。如果你思考过,你会发现世界其实差不多就是这么运作的。只有当条件匹配为真的行才会被检索到。当条件为假或者我们不知道那这行就不会被检索到。
如果我们在真值表中引入“不知道”可以看到如 图2-7 的所示。在 AND 操作符下,只要一个表达式是假,其他表达式就不再需要关注,结果必然为假,而一旦存在不知道,则不管条件真假,结果均为不知道。在 OR 操作符下,只要有一个表达式为真,其他的表达式就不需要再关注,结果必然为真,而一旦存在不知道,则不管条件真假,结果均为不知道。注12。
图2-7 三值逻辑真值表(T=真,F=假,?=不知道)
管理重复数据(duplicates)
如果我们好好设计表,这些表都应该有一个主键。这表示每一行都具有唯一性。但当我们从表中检索出数据时,这个子集可能会失去唯一性注13。让我们看一个例子。
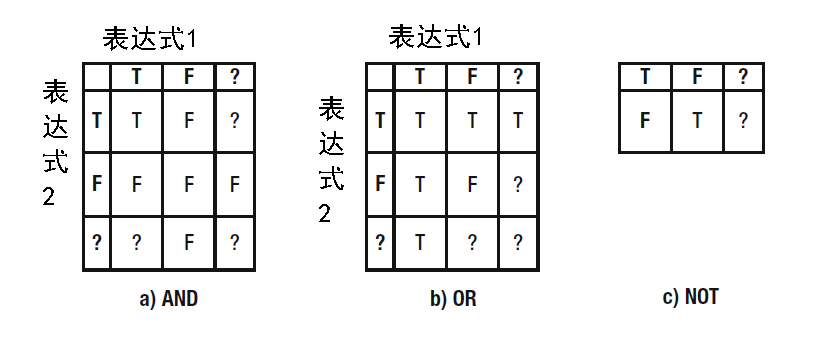
想要从 Member表 中仅仅抽取出 FirstName,图2-8 给出了两个可能的结果。
图2-8 从Member表 中找到FirstName字段
我们非常有必要去想一想为什么要去执行一个只搜索名字的查询。或许是俱乐部要准备一套会员的名牌。在那种情况下,我们输出的结果都是唯一的话,那两个 Thomas 和一个 William 将会被漏掉。
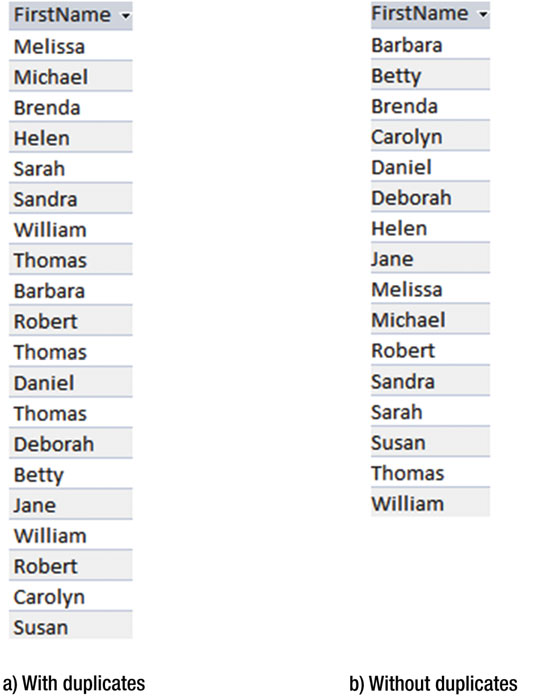
你可能会想,是不是有点小题大作了?当然,我们希望得到的结果有所有行。但也要想到只通过会员类型(membership type)来检索。图2-9 分别显示了所有包含重复数据和删除了重复数据的输出结果。
图2-9 从Member表 中找到MemberType字段
很难有一个漂亮的方案可以从 图2-9a 的重复数据中找到你要的。上述两个操在自然语言中看起来非常相似。“给我一份会员名字的列表”和“给我一份会员类型列表”就像是同一个问题,但却有本质上的不同。第一句话的意思是“给我一份每个会员名字的列表”,而另一句则是“给我不重复的一份会员类型列表”。
SQL 要怎么写?如果我们写 SELECT MemberType FROM Member,我们会得到 图2-9a 中那样有重复数据的结果。如果我们不想要重复数据,我们可以用 DISTINCT关键字。
SELECT DISTINCT m.MemberType
FROM Member m
是否要保持重复数据很多时候是由你的需求决定的,所以你需要谨慎思考。如果你期待获得 图2-9b 但得到的却是 图2-9a,那你就需要多多留意了。像 图2-8 的所示更难让你去区分是否发生了错误。把考虑查询中是否需要重复数据当成一个习惯。
给输出排序
我会经常引用“结果集(set of rows)”而不是表或虚拟表。结果集这个词中的“集”有两个意思。一是这其中没有重复数据(我们已经讨论过很多次了!)。第二个意思是这个集合没有定义怎么排序。从理论上来说,我们并不知道谁是第一行,谁是最后一行或者下一行。如果我们用一个查询去表中检索所有的数据,或者某些数据的时候我们没有规定要以怎么样的方式来排序。但是,有些时候我们却希望结果能以一个特定的方式来排序。我们可以通过 ORDER BY 子句来实现这个功能。下面就展示了怎么通过指定 LastName 按字母顺序来给结果进行排序。
SELECT *
FROM Member m
ORDER BY m.LastName
我们可以通过更多的值来排序。比如我们想要通过姓、名分别排序的高级会员,就可以加入在 ORDER BY 子句中加入两个属性:
SELECT *
FROM Member m
WHERE m.MemberType = 'Senior'
ORDER BY m.LastName, m.FirstName
这种类型的字段决定了数据怎么去排序。默认排序、文本排序等都会通过字母顺序来排序,数字则是从小到大排列,时间和日期则按照时间顺序排列。我们也可以通过指定关键字 DESC 来进行降序排列。它还有个对等关键词 ASC 可以进行升序操作,这是 SQL 的默认值所以不用特别指明。下面的代码会返回用户名和差点,并通过差点倒序来实现分数从的高到底排列。
SELECT m.Lastname, m.FirstName, m.Handicap
FROM Member m
ORDER BY m.Handicap DESC
在这种时候,null 会以什么方式输出就完全取决于各个数据库软件,所以需要加以鉴别。比如在 SQL Server 和 Access 中,null 会排列在顺序列表的顶部或者降序列表的尾部。Oracle 提供了像 NULL FIRST 和 NULL LAST 这样的关键字所以你可以自由选择怎么去排列 null 值。这里有一个在 SQL Server 中通过 case 语句来实现将 null 值排列在 SQL 最尾部的小技巧:
SELECT m.LastName, m.FirstName, m.Handicap
FROM Member m
ORDER BY (CASE
WHEN m.Handicap IS NULL THEN 1
ELSE 0
END), m.Handicap
上面查询中的 ORDER BY 字句中有两个属性。它首先用过括号中的 case 语句进行排序。你可以认为 case 语句创建了一个虚拟的字段,并将有差点值的行设位 0 ,没有差点值的行设为 1 。当我们通过这第一个属性来排序时,所有有差点值的行都会先于 null 值出现。而在每个分组内则通过差点值的升序来为所有行排序。
进行简单的统计
和从表中取回一个行和字段的子集一样,我们也可以使用 SQL 查询去进行某些统计。有很多 SQL 函数可以让我们去进行结果统计,算总分或者平均值,找最大最小值等等。在这里,我们会看一些简单的数据统计例子。我们会在 第8章 中再回头再来详细说这些例子。
我们可以通过 COUNT 函数来得到 Member 表中记录的数量。在下面的查询中 * 表示统计整个表中的所有记录。
SELECT COUNT(*) FROM Member
我们也可以通过添加 WHERE 字句来指定要统计的是表中的哪些记录。比如,我们可以像下面的查询那样去指定要统计所有高级会员。
SELECT COUNT(*) FROM Member m
WHERE m.MemberType = 'Senior'
因为我们有着 null 和各种重复的数据,我们会讲一讲这些数据是怎么影响我们的统计结果的。如果不想在 COUNT 函数用 * 代表所有字段的参数,我们可以把像差点(Handicap)这样的属性当作参数。如果我们这么做那就只有差点属性的数据会被统计注14。
SELECT COUNT(Handicap) FROM Member
我们也可以指定我们想要统计的某个属性为唯一值。如果我们想要知道在 Member 表中有多少 MemberType 那我们就可以用下面的查询:
SELECT COUNT(DISTINCT MemberType) FROM Member
需要说明的是在不同的数据库软件中这个查询可能会得到和 SQL 标准不同的结果。比如 Access 不支持 COUNT(DISTINCT MemberType) 。一般来说都会有其他等效替代方法来解决这些差异,我们会在 第8章 中去了解怎么去重构前面的查询,还有与聚合(aggregates)以及汇总(summaries)有关的其他问题。
避免常见错误
从一个单表(single table)中获得一定行列的子集是最简单 SQL 查询。但即便如此也得千万小心。非常重要的一点是需要记住表中会有 null 值,需要仔细思考该使用怎么样的条件去处理它们。你也需要记住如果,如果你不准备在结果中保留表的主键,那结果就可能会有很多重复数据,所以你必需要把它们及时处理掉。
在选择一个子集的时候还有一些其他的错误。它们在 Member 表中的表现并不那么明显,所以我会在高尔夫俱乐部中引入更多的表。图2-10所是的部分 Member 表和其他两张表:Entry 和 Tournament 。Entry 表中的第一行数据记录了 118号 会员(Melissa McKenzie)在2014年参加了 第24场 比赛(Leeston)。
图2-10 引入Tournament和Entry表
我们可以通过某些作用于 Entry 表上的某些 SQL 操作来应对需求,比如 258号 会员参加过哪场比赛(场次号),谁(会员编号)又参加了 第24场 比赛,或者谁在 2015年 参加了 第36场 比赛。下面的 SQL 是之前说的最后一个的查询:
SELECT e.MemberID
FROM Entry e
WHERE e.TourID = 36 AND e.Year = 2015
错误使用 WHERE 子句来对应“都(both)”这个需求
在上面的操作中,我们使用了 AND 这个逻辑操作符去 Entry 表中查找符合 TourID = 36 且 Year = 2015 的数据。
当我们想要知 第36场 和 第38场 比赛都参加的会员是哪些人时,可能会被误导再次使用 AND 操作符去写查询,就像下面这样:
SELECT e.MemberID
FROM Entry e
WHERE e.TourID = 36 AND e.TourID= 38
你能告诉我上面的查询会返回什么吗?通过 图2-11 中 Entry 表中通过 e 指代的那行数据就很容易的得出结果。
图2-11 行内指示符(row variable)e指向的每一行的数据都是独立的
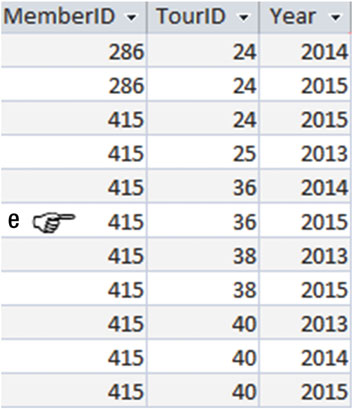
看一下上图中手指所指的那行数据。这行数据(415,36,2015)能被 e.TourID = 36 AND e.TourID = 38 所获取到么?它可以匹配第一部分,但无法通过 AND 操作符来满足所有的条件。在我们的表中没有哪行数据可以满足即是 第36场 又是 第38场 的比赛,因为一行数据只对应一场比赛。用上面的 SQL ,我们永远也找不到任何数据,它会返回一个空表。如果我们将布尔运算符修改为 OR ,我们就会得到类似 图2-10 中所示的结果。因此我们得到的数据中即有 第36场 也有 第36场 的比赛。
但是特殊的查询无法通过单条件的 WHERE 子句来解决。通过定义可知,WHERE 条件对每一行的数据都是独立的。想要回答“谁参加了多场比赛”这个问题,党我们需要同时去看 Entry 表中的多条数据的时候,就需要其他的手指了。如果我们有两根手指,一个点在 图2-10 中所示的行上,另一个点在下一行上,那我们就可以发现我们要找的比赛都有 415号 会员参加。我们会在 第5章 中说明是怎么做的。
错误使用 WHERE 子句来对应“非(not)”这个需求
现在让我们来看看另一个常见的错误。通过条件 e.TourID = 38 很容易发现有哪些会员参加了 第38场 比赛。稍稍改变一下查询条件来获得那些没有参加 第38场 比赛的人。你能指出下面的 SQL 会查询到什么吗?
SELECT e.MemberID
FROM Entry e
WHERE e.TourID <> 38
上面的 SQL 是不是就是 图2-11 中有手指的那一行呢?它是不是满足 e.TourID <> 38 这个条件?当然是的。但这并不能表示 415号 会员没有参加过 第38场 比赛(手指所在行的下一行表示 415 号会员参加过 第38场 比赛)。事实上,这条查询返回了除了 第38场 比赛外所有人的所有比赛记录(这完全就不是你想要知道的!)
这又是另一种类型的问题,无法通过单条件的 WHERE 子句来定位表中所有独立的行。事实上,我们无法在查询中只通过 Entry 表来解决上面的问题。138号 会员的 Michael Stone ,没有参加 第38场 比赛。因为他从来没有参加过任何比赛,所以他甚至都没有被记录在 Entry 表中。 我们会在 第7章 中来解决类似的问题。
小结
在这一章中,我们看了一些单表上的查询。总结一下重点:
- 我们可以通过
WHERE子句来得到满足指定条件的行的子集。条件是一个布尔表达式,结果不是true就是false。条件独立作用于表中的每一行数据上。 SELECT子句让我们指定想要筛选的列。- 因为查询的结果是行的集合,所以为我们无法保证结果会以何种顺序返回。如果我们想要结果以特定的顺序排序,可以适用
ORDER BY子句。 - 可以创建一个视图,实际上值是将 SQL指令 保存下来,以便你可以在目标表的数据被修改以后一次次地重复运行。
- 表中经常因为有意无意的原因而产生 null 值。总是要检查你的查询条件是否考虑到了 null 。
- 当你用 SQL 去投影字段的子集时,默认会保存所有的重复数据。总是要想一想你是否徐亚这些重复数据,以及可以用
DISTINCT关键字来去重。 WHERE子句一次只会作用一行。不要将它用于需要一次查出多行数据,比如想知道谁参加了多场比赛,或者都有哪些人没参加某场比赛。注15
译注
注0. 因为列和字段对应的单词都是 column ,所以今后如果不造成歧义,将不再刻意区分,看到哪个合适就用哪个。 ↩
注1. 原书注:In the formal terms of relational algebra, retrieving a subset of rows (tuples) from a table (relation) is known as the select operation and retrieving a subset of attributes (columns) is known as the project operation. See Appendix 2 for more information.
中文翻译:关系代数的正规描述中,从一个表(关系)中获取行(元组(tuples))的子集叫做选择(select)操作,而获取属性(字段)的子集叫做映射(project)操作。详情见 附录2 。 ↩
注2. 布尔表达式只有两个值:真和假,本节中所有的“逻辑表达式”一词都是指代“布尔表达式”,其他具体的说明参看本节内容。 ↩
注3. ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准 ISO/IEC646。ASCII 第一次以规范标准的类型发表是在 1967年 ,最后一次更新则是在 1986年 ,到目前为止共定义了 128 个字符。
参考网站:http://www.asciitable.com/ 。 ↩
注4. Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年 开始研发,1994年 正式公布。 ↩
注5. 这里的原文是:“that is, you are happy to retrieve rows where MemberType is “Junior” or “jUnIoR” or whatever”,我有些不太理解其中“happy”的意思,所以姑且按现在这么来翻译。但这里总感觉上下文的逻辑有些奇怪,留着以后再改。 ↩
注6. UPPER函数 为每个文本单独进行处理,并当所处理的文本不在 a-z 的范围内时,该函数不做任何处理。 ↩
注7. 这里的原文是“social member”。因为不知道 social 一词所代表的具体含义,不好翻译,所以姑且翻译成为“特别会员”。 ↩
注8. 真值表是表征逻辑事件输入和输出之间全部可能状态的表格。列出命题公式真假值的表。通常以T(true)表示真,F(false)表示假。命题公式的取值由组成命题公式的命题变元的取值和命题联结词决定,命题联结词的真值表给出了真假值的算法。
参考资料:https://baike.baidu.com/item/真值表。 ↩
注9. 这里的意思是,一个逻辑表达式为真的情况下,取其“非”值,就是“非真”。而因为布尔表达式只有真和假两个值,所以非真=假。
反之,如果一个逻辑表达式为假,其非值就是非假=真。 ↩
注10. 主流数据库软件都应该禁止主键为空,也就是默认主键都是 NOT NULL 的状态。 ↩
注11. 因为不明白差点是怎么获得的,所以将原文中的“do not have handicap” 翻译成“都没有参加过比赛”。 ↩
注12. 这里的描述有点怪,和下面的真值表对应不起来,姑且按我的理解加入了有关“不知道”的部分(粗体字)。 ↩
注13. 原书注:Formally, in terms of relational algebra, the result of every operation will generate another relation or set of unique rows.See Appendix 2 for more information.
中文翻译:从表面来看,通过关系代数,每个操作的记过豆浆变成另一组关系或者集合的唯一行。更多信息见 附录2。 ↩
注14. 言外之意是,如果属性字段中如果有 null 值,则该行数据则不会被统计。 ↩
注15. 这里的逻辑有些漏洞,最好加上“单条件的”限定。 ↩