第三章 首先来看连接(JOIN)
通过前面的章节,我们学习了怎么从单表中查找行或列的子集。第1章 中,我们学到了怎么把数据准确的存入数据库,信息的不同切片(aspect)都要存到对应的规范化的表中。很多查询都要从两张甚至更多的表去引用信息。我们可以用多种方式把两张表里的数据的属性组合成我们想要得到的样子。两张表间最常用的关联操作就是联合(JOIN)。在 第1章 中,我也介绍过两种不同的查询方法:过程方法和结果方法。第一种方法介绍了我们是怎么通过组合表来获得所需要的数据的,第二种方法则说明了被检索的数据要满足怎么样的条件。
连接的过程方法
连接可以让我们绑定有关系的两张表。让我们以 Member 表和 Type 为例,列出高尔夫俱乐部中每个成员的会费。通过连接筛选数据的第一步操作被称为笛卡尔积(Cartesian Product)。
笛卡尔积
笛卡尔积可以以任何意形式作用于任意两张表,因此成为了两表间最频繁的操作。也正如此,笛卡尔积可以提供的有效信息非常少,因此它最主要的作用就是连接的第一步。
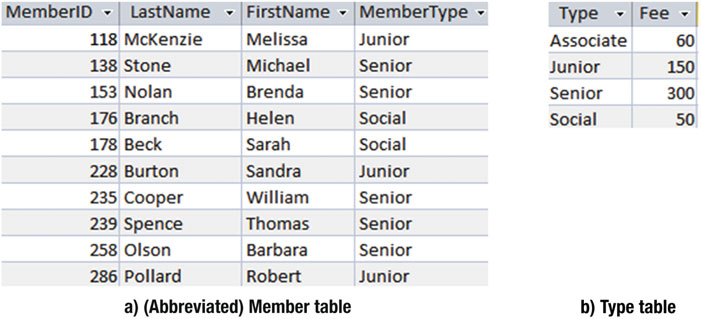
笛卡尔积有点像是把两张表并排放在一起。让我们看看 图3-1 中所示的两张表:一张有所删节的 Member 表和一张 Type 表。
图3-1 数据库中的两张永久表
通过笛卡尔积得到的虚拟表会让其每一个字段都可以对应原始表中的字段。结果表中的每一行数据都来自原始表。图3-2 就展示了笛卡尔积中的前几行。
图3-2Member表和Type表的笛卡尔积的前几行
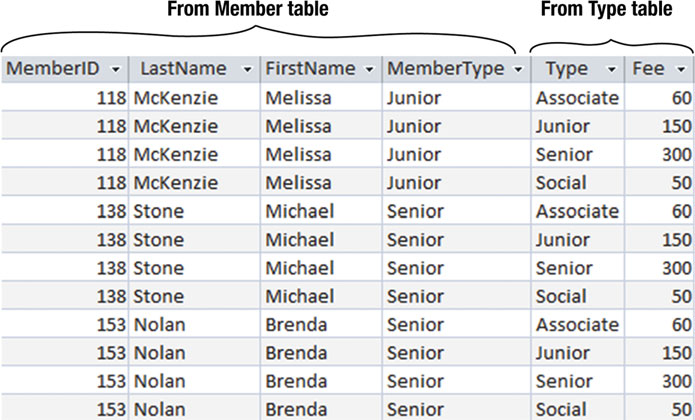
在上述的六个字段中,其中有四个字段来自 Member 表,另外两个字段来自 Type 表。每行来自 Member 表数据的一旁一定是来自 Type 表的数据。Melissa McKenzie 对应了四行数据—— Member 表中的数据匹配了 Type 表中的所有数据(Associate, Junior, Senior, Social)。而总的行数就变成了两张表的行数之积。换句话说,在上面裁剪后的 Member 表我们要在 10 行数据之上再乘以 4 行(来自 Type 表),结果就变成了 40 行。笛卡尔就会返回一个非常非常大的结果集,这也是为什么它给不了多少有用信息的原因。
笛卡尔积在 SQL 中可以通过 CORSS JOIN 来实现。而如 图3-2 中所示的结果用到的 SQL 是:
SELECT *
FROM Member m CROSS JOIN Type t;
不是所有版本的 SQL 都支持相同的关键字和句式(phrase),比如 Access 2013 就不支持 CORSS JOIN 句式。1992 年,SQL 标准注0加入了一些表示关系代数操作符号关键字,比如 CORSS JOIN。SQL标准从那之后又更新过许多次,但并不是所有的厂商都支持全部标准,一些其他厂商额外提供了更多的其他功能注1。在这一章的后续中,我们会讨论当关系代数的关键字不可用时,通过结果方法所达到的同等的查询效果。
内连接(INNER JOIN)
如果关注 图3-2 中的表,你可以发现很多行兵没有太多的意义。比如第一、第三、第四行的数据,初级会员的 Melissa McKenzie 却显示其为临时会员、高级会员和特别会员。很难看出这些数据究竟会有什么用。注2如果我们只把 Member 表中的 MemberType 字段和 Type 表中 Type 字段相匹配的行拿出来,我们就得到了我们想要的信息,比如每个会员的会费。图3-3 就展示了这点
图3-3 从笛卡尔积中筛选出子集
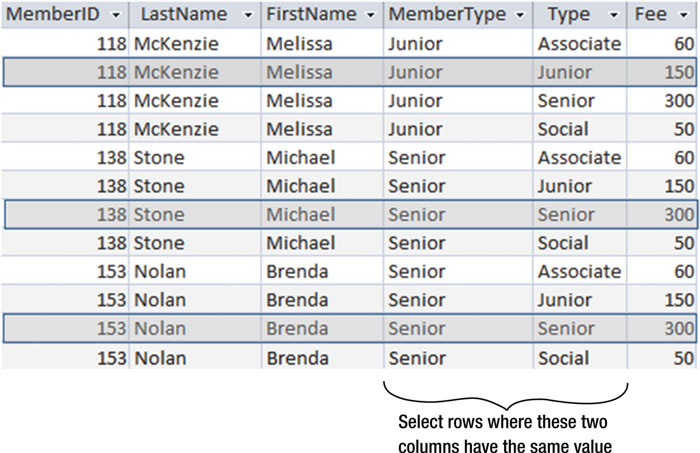
图3-3 的所示的操作(从笛卡尔积中筛选出一个子集)被称为内连接(简称连接)。所使用的行查询条件也被称为连接条件。图3-3 的 SQL 如下:
SELECT *
FROM Member m INNER JOIN Type t ON m.MemberType = t.Type;
在通过使用关键字 INNER JOIN 之后,我们可以看到为了筛选出所要的行而用了关键字 ON 。再说一次,某些版本的 SQL 并不支持 INNER JOIN 句式。所以,我们会在这一章的稍后中讲述其他的查询方法。
我们所要进行连接的两个字段(MemberType 和 Type)是必须可以被连接(join compatible)的。专业点说,就是它们必须来自相同的取值范围或者可能的值的集合。实际上,可以被连接通常也就表示那些字段在不同的表中都有着相同的数据类型。比如都是数字或者都是日期的字段。不同的数据库可能会对连接的兼容性有着不同的处理。有些数据库会允许一张表示浮点数而另一张表示整数的连接。有些数据库或许会要求文本字符的宽度都要一致(比如 CHAR(10) 或者 CHAR(15)),而其他的就不行。我建议不要去尝试着连接不同的类型,除非你非常清楚你在干什么。和之前一样,最好的方法就是在你设计表的时候就想清楚。把那些可能要做成连接的属性都设置为同一个类型。
连接的结果方法
让我们来看看用结果方法进行进行连接。先不去管怎么组织表,而是去看看要检索出目标行需要满足哪些条件。
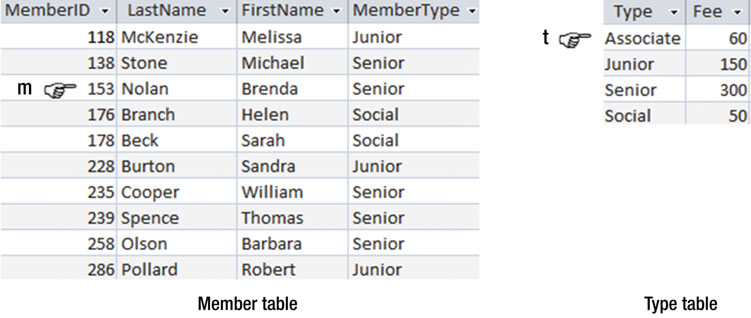
让我们通过笛卡尔积来开始:我们需要一个由有效的表的有效的行组成的集合。图3-4 告诉了我们怎么去构想这种关系。我们看到这两张表,所以我们需要两个指示符来标记行。指示符m 在 Member 表中都有对应的值。当然,它现在在第 3 行。Member 表中的每一行,指示符t 都可以在 Type 表中找到对应的值。通过笛卡尔积我们可以知道所有的有效行。更明确地说,图3-4 的笛卡尔积云云说得更直点就是:
我会把所有来自
Member表中的 m 行的所有属性 和所有来自Type表中的 t 行的所有属性都保留下来
图3-4 行内指示符 m 和 t 各自指向Member表和Type表中的每一行
如 图3-4 所说的查询 以及 图3-2 那样的输出结果的 SQL如下:
SELECT *
FROM Member m, Type t
上面的 SQL 会返回我们之前所描述过的 CORSS JION 的相同的结果。
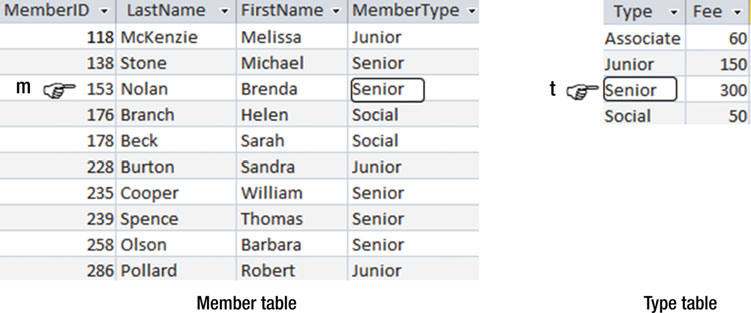
在使用 JOIN 进行搜索的时候,需要指定对于特定的数据不管在哪张表中都相同的额外搜索条件。说得更直点就是:
我把所有来自 m行 的属性和来自 t行 的属性全部列出,只要 m 来自于
Member表,t 来自于Type表,以及m.MemberType = t.Type。
图3-5 描述了一对满足搜索关系的行。如果让 m 保持原位,而 t 下降一行,那么两者之间的条件关系就不再被满足,也就无法再获得合适的数据。
图3-5 当m.MemberType = t.Type时行就会被查找出来
我们可以把 图3-5 中描述的查询翻译成以下 SQL:
SELECT *
FROM Member m, Type t
WHERE m.MemberType = t.Type;
如果我们仔细看一下上面的 SQL ,可以看到在最开始的两行表达了笛卡尔积,还有 WHERE 子句在最后一行选择了两张表中会员类型一致的子集。这就是我们在之前的章节中讲过的内连接。下面用内连接写成的 SQL 会和前面的 SQL 会找到相同的行,再看一眼:
SELECT *
FROM Member m INNER JOIN Type t ON m.MemberType = t.Type;
第一种 SQL 表达了要查找哪些行(结果方法),之后的 SQL 表达了我们允许采用哪些操作去从行中查找数据(过程方法)。使用那种方法并不重要,重要的是要学会去思考怎么构筑查询。有些时候你选择的方式会影响到查询的性能,我们会在 第9章 中进行详细说明。事实上,大多数数据库要么会对 SQL 进行优化;要么直接找一个执行速度快的查询方式,而根本不管你怎么写。比如 SQL Server 对 JOIN 的两种表达都采用了同样的方式。SQL Server 2013 在实际操作中如果采用默认的界面写第一种 SQL 生成一个视图,程序会自动把代码转换成使用 INNER JOIN 的形式。
扩展连接查询
既然我们已经把连接加入了仓库,我们就可以执行多种类型的查询了。因为含有操作的查询的结果是在另一张表中,我们可以稍后连接那个结果去第三张表,或者其他表,最后选择想要行和列找到想要的结果。
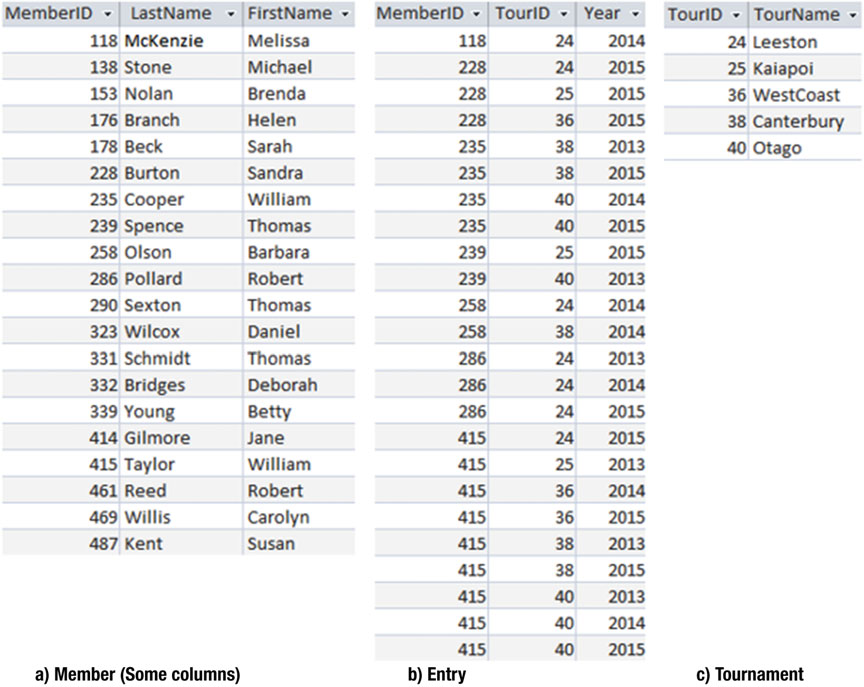
让我们看一下 图3-6 中几张表的例子。Entry 表使用了两个外键(foreign key)MemberID 和 TourID 用来维持那些参加过不同比赛的会员的信息。Entry 表中的第一行数据记录了 118号会员 在 2014年 参加了 第24场 的比赛。如果我们想要更多的信息(比如会员姓名、比赛名称),我们需要利用外键在 Member 表和 Tournament 表从中找各自寻合适的行。
图3-6 俱乐部数据库中的永久表
让我们找到在 2014 年中所有名叫“Leeston”的比赛。我会描述两种不同的方法,以及你或许会找到一个或者更多的其他方法。
一个过程方法
我们从三张表开始,所以我们需要一些操作来组合这三张表中的数据相互融合。我们将 Member 表 连接到 Entry 表,然后把连接后的结果集和 Tournament 表再进行连接,如 图3-7 所示。
图3-7 联合Member、Entry、Tournament三张表
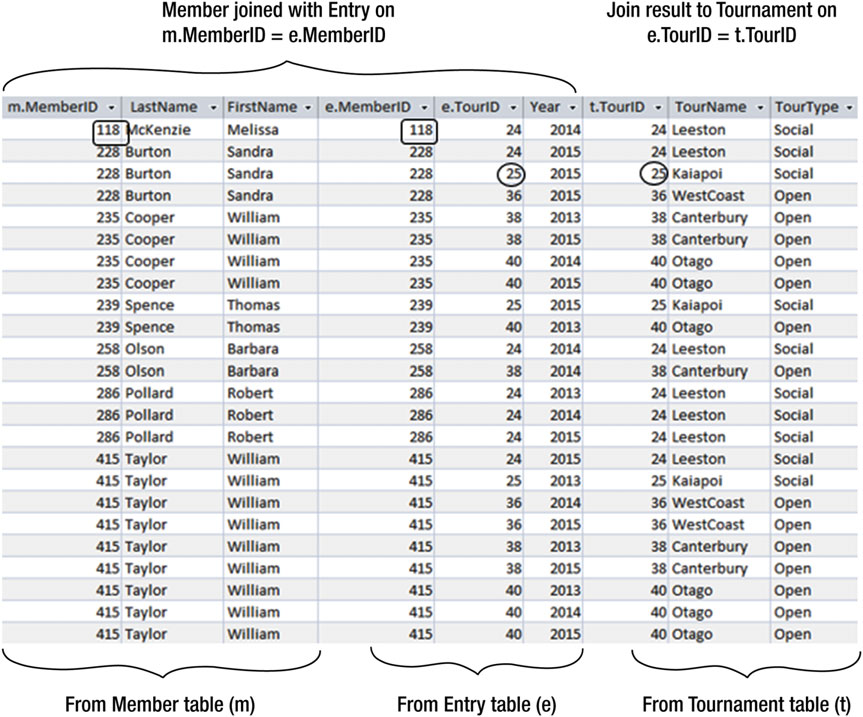
第一次连接在 Member 表和 Entry 表之间通过 m.MemberID = e.MemberID 的条件来进行结合,就像 图3-7 中的矩形块框出数据的所示。第二次连接在第一次连接的结果集和 Tournament 表之间通过 e.TourID = t.TourID 的条件来结合,就像 图3-7 里的圆所圈出的数据所示。不管我们是先连接 Entry 表 和 Tournament 表,还是先联合 Entry 表 和 Member 表都没有太大的差别。
把两个连接写成 SQL :
SELECT *
FROM (Member m INNER JOIN Entry e ON m.MemberID = e.MemberID)
INNER JOIN Tournament t ON e.TourID = t.TourID;
通过连接查询得到的虚拟表的结果集包含了我们所想要的全部信息。我们仅需要将满足年和比赛名称的行通过 WHERE 子句筛选即可。然后就可以通过在 SELECT 子句中指定属性的名称来将他们映射到最终的结果中。完整的 SQL 查询返回了“参加过在 2014年 举办的名为‘Leeston’的比赛所有会员的姓名”:
SELECT LastName, FirstName
FROM (Member m INNER JOIN Entry e ON m.MemberID = e.MemberID)
INNER JOIN Tournament t ON e.TourID = t.TourID
WHERE TourName = 'Leeston'
AND Year = 2014;
换种方法
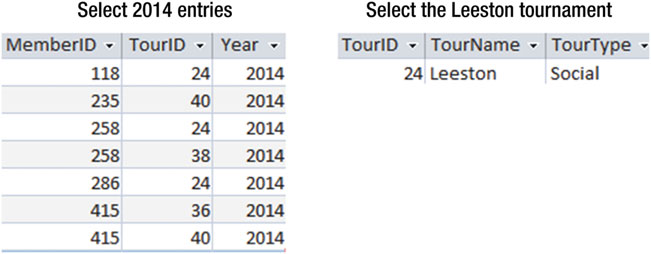
在上面的章节中,我们首先把所有的表都进行了连接,然后再找到对应的行和列,连接的结果如 图3-7 所示的中间表。如果有非常多的会员和非常多的比赛,这个中间表将会非常非常之大。我们可以用不用的操作顺序来执行这些操作。我们可以先仅在 Tournament 表中搜索“Leeston”和在 Entry 表中搜索“2014”,就如 图3-8 的所示。把这两张较小的表进行连接后再和 Member 表进行连接,就会得到一张小的多的中间表。
图3-8 在联合前分别重Member、Entry、Tournament中找出数据行
所以我们搞错了操作的顺序么?回答是:是——操作顺序不一会有巨大的差别——但当你用 SQL 时,不用去考虑这些问题。不管 SQL 怎么写都被同样的执行。所有 SQL 语句在执行前都会被你所使用的数据程序进行优化。这表示数据库程序会找到最合适的方法去执行。某些数据库程序做的非常好,有些却不怎么样。很多数据库程序有可以让你查阅的执行了怎么样的查询的统计工具。对很多查询来说,你写出的 SQL 并不会对实际运行产生多少差异,但你可以让查询的效率变得更高,比如给表加上索引g(index)。我们将会在第九章中详细的探讨这些问题。
一个结果方法
我们所便编写的 SQL 通常并不影响查询的效率是因为 SQL 都基于关系算法,描述了查询到的行多必须满足的条件注3。最初的 SQL 标准中甚至没有像 INNER JOIN 这样的关键字。在 SQL 没有这些关键字就没法描述想要获得的数据该是怎么样的,因为它们没有办法描述它们是怎么工作的。让我们来看看怎么通过结果方法来找到谁在 2014 年参加了名为“Leeston”比赛的会员。
我们只想从 Member 表中得到一些名字。忘了连接,在你完全不知道外键、连接以及其他数据库等知的情况下,你会怎么从眼前这三张表中找到某个特定的名字。把手指指向某张表中的记录,就像下面的 图3-9 中所示的那样。
图3-9 通过行内指示符去描述满足搜索条件的行
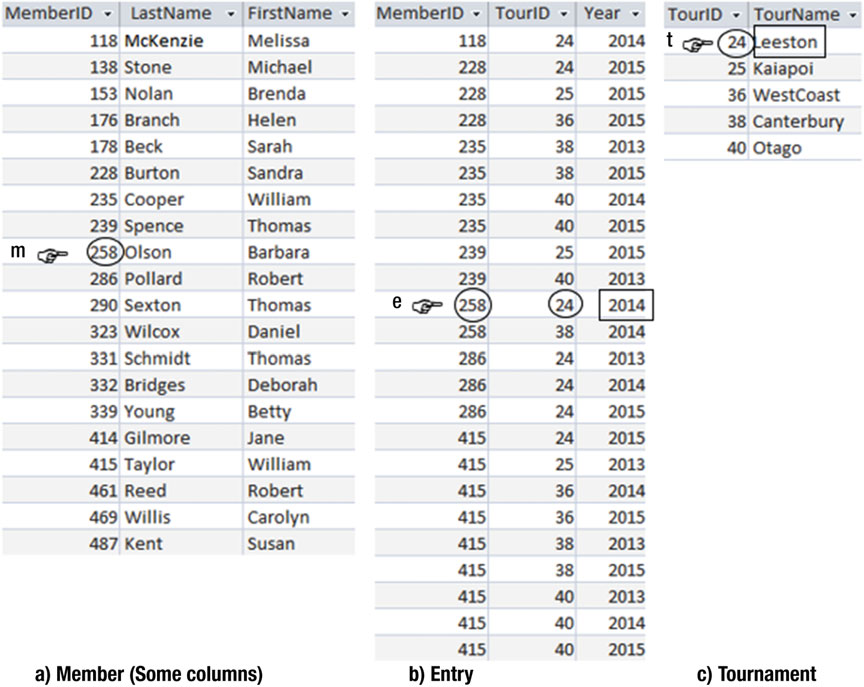
当我们去找 Babara Olson 这个名字的时候,怎么知道 图3-9 中的哪个 m 才是我们想要的目标?我们是怎么知道的?首先,我们先在 Entry 表中找到她的 ID(235)所对应的在 2014 年的那行数据。然后我们
必须在 Tournament 表中找到 Leestion 比赛所对应的行,并确认其 id 是 24 。再观察 图3-9 ,我们发现那些刚刚找到的行在每个表中都有一个指示。这样就有了足够的信息来让我们知道 Barbara Olson 到底参加了 2014 年的哪场 Leeston 比赛。这些条件表达了表里的每行数据都是怎么储存的。
现在让我们把最后一段写的更简洁一些。参考下面的句子去理解一下在 图3-9 中所要找数据的行数据。
我如果要从
Member表的m行中找到名字,就得从Member表中找到记录m、Entry表中找到记录e,以及从Tournament表中找到记录t,并确认m.MemberID和e.MemberID一致,e.Year是 2014,e.TourID和t.TourID一致,t.TourName的值是 Leeston 。
仔细观察下面的实现了如 图3-9 效果的 SQL。
SELECT m.LastName, m.FirstName
FROM Member m, Entry e, Tournament t
WHERE m.MemberID = e.MemberID
AND e.TourID = t.TourID
AND t.TourName = 'Leeston' AND e.Year = 2014;
你可以看到 SQL 是怎么表达应该去检索怎么样的行的。如果你仔细观察 SQL 语句,也可以找到对应的操作。第二行的 FROM 子句是一个巨大的笛卡尔积,再下面两行是关联条件(图3-7 所说的“从那张表中得到怎么样的数据”),最后一行通过年份和和比赛名称的对应关系来找到所要的行,最后用 SELECT 行让我们得到想要的名字。
这句 SQL 等效于之前我们用的 INNER JOIN 关键字的那句 SQL 。他们都会返回相同的结果集:但一个体现的是怎么去做,另一个体现的是想要得到什么。
通过图像化的方式表示连接
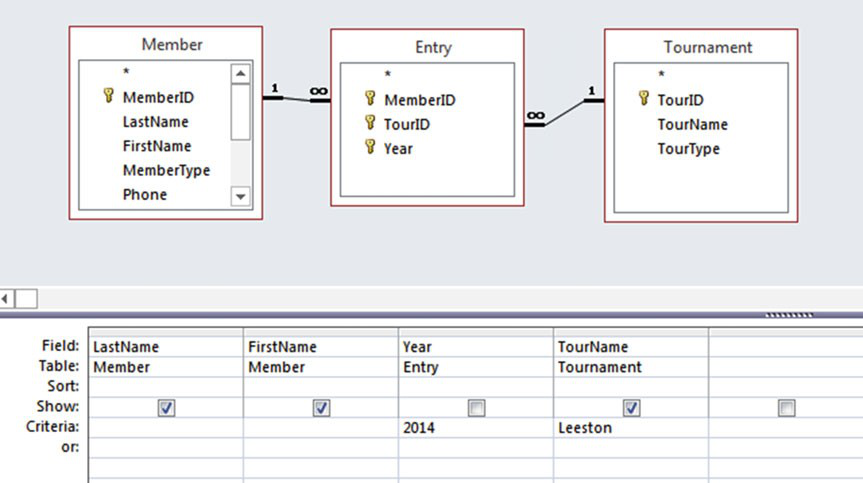
这是一本关于 SQL 查询的书,同时大多数据库也提供了图形界面来帮助查询。在最后,我会通过图形化的方式来展示如何去查找谁在 2014 年参加了 Leeston 比赛。
图3-10 虽然是 Access 的图形界面,但大多数数据库的界面都很相似。上半部分的长方形表示表,表之间用线连接表示两者的关联关系。在 Show 那行,所有需要字段都带有一个确认符号(√),还可以在 Criteria 行中为要进行搜索的条件输入详细的值。
图3-10 通过 Access 的图形界面查找参加过 2014 年 Leeston 比赛的会员姓名
其他的连接类型
在本章中我们所研究的连接方式被称为同等连接(equi join)注4。同等连接的联合条件中只包含等号操作符,就像 m.MemberID = e.MemberID 。这是最常见的条件,但你也可以用不同的操作。连接仅仅是把笛卡尔积选出子集而已,可以选择不同的算数运算符(比如<>、>),可以是逻辑运算符(例如 AND 或者 NOT )。虽然这类连接并不常用。
你可能也听说过自然连接(natrue join)注5。自然连接假设所有表中要被连接的字段的名字都一致。关联条件是具有同名的字段,并在结果集中删除其中一个字段。例如:
SELECT * FROM implicitly
Member NATURAL JOIN Entry;
等效于:
SELECT * FROM
Member m INNER JOIN Entry m ON m.MemberID = e.MemberID;
在上面的自然连接示例中,连接条件默认会先去寻找两个同名的属性MemberID。两个查询间的唯一差别就是自然链接只会返回一个 MemberID 。 Oracle 支持自然链接,而 SQL Server 和 Access 不支持自然链接。
外连接
外链接(outer join)是经常被使用的连接方式,所以需要重视并理解它。理解外连接最好的办法就是看一下它们都用在哪里。看一下 图3-11 中被修改之后的 Member 和 Type 二表。
图3-11Member和Type表
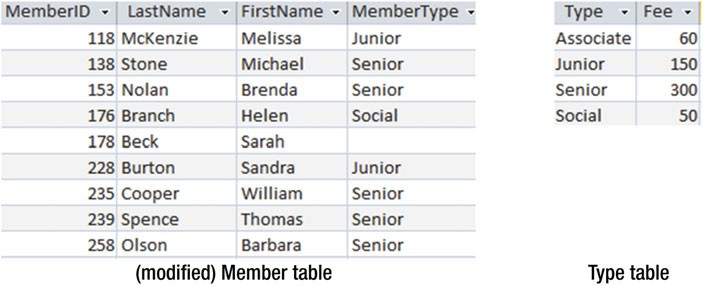
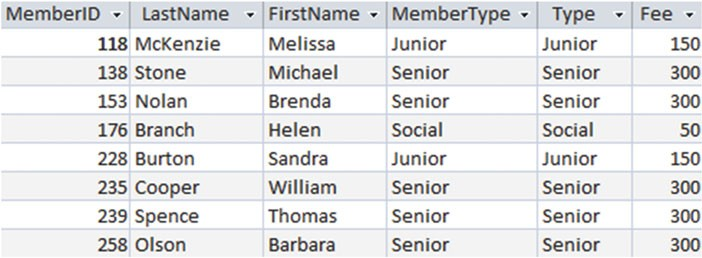
你希望可以从 Member 表中找到不同的地方,比如数字和名称、名称和成员类型等等(如 图3-11 所示表应有 9 行)。然后你可能会想,除了会员列表中所看到数字和名字,还有会员费(memmbership fee)。你通过通过 Memeber = Type 关联在一起的表发现“少”了一个会员——Sarah Beck(见 图3-12)。
图3-12 内连接后的Member和Type表,以及丢失了 Sarah Beck
原因是 Sarah 在 Memeber 表的 MemeberType 字段中没有值。让我们通过笛卡尔积来看看连接的第一步会做些什么。图3-13 展示了笛卡尔积是怎么包含 Sarah 的。
图3-13Member和Type表的部分笛卡尔积
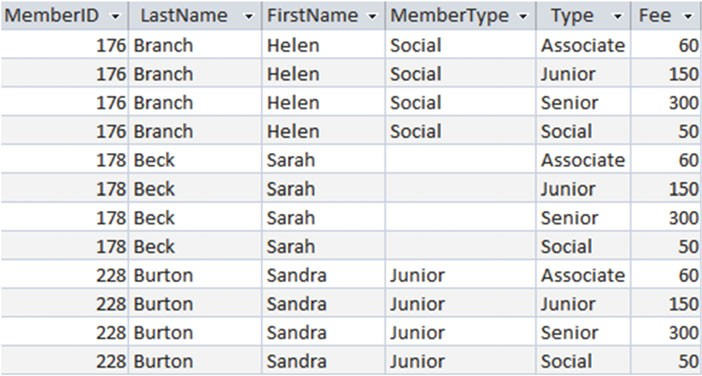
我们需要在通过笛卡尔积中去操作满足条件( Member = Type )的连接的最后一步。就像你在 图3-13 中所看到的,结果中并没有把 Sarah 统计进来的原因是她的 MemerType 的是一个空值注6。
思考一下下面两句自然语言之间的差别:“给我会员的付费信息”和“给我所有包括缴费和没缴费的所有会员的信息”。第一句话的意思是“告诉我哪些会员交了费”而第二句话更想说的是“给我所有的会员,并告诉我他们的交费情况”。最大的困难之一是在写查询的时候怎么去确定你想要得到的是什么。而当你想去理解其他人的想法时,就更加困难了!
假设我们真的想要是一份所有会员的名单,以及包括了会员付费信息的列表。在本例中,我们希望看到 Sarah Beck 可以出现在结果中,并且显示没有付费。这就是外连接所要做的。外连接有三种形式:左外连接、右外连接、全外外连接(full outer join)。左外连接从左表中检索出了包含了有 null 值的所有行,就像 图3-14 所示的那样。我们可以看到所有通过 inner join 检索出来的行(图3-12),我们也可以看到一行从Member 表中搜索出来关于 Sarah 的行。这行数据在 MemberType 表中对应的值是 null 。这行数据中,那些从右手表(righ-hand table)比如 Type、Fee 中的字段都是 null 值。
图3-14Member和Type表的左外连接结果
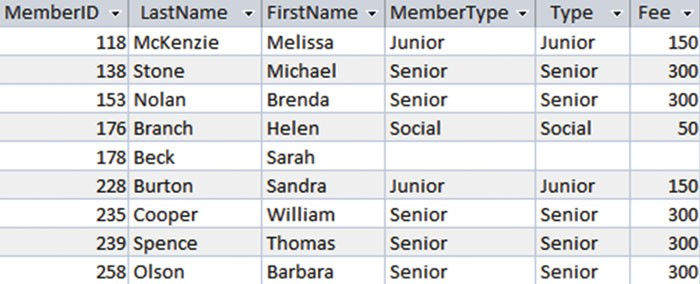
通过 图3-14 所展示的可以看出,SQL 中左外连接和内连接非常相似,但关键字 INNER JOIN 却被替换成了 LEFT OUT JOIN (在某些数据库也可以缩写为 LEFT JOIN)。
SELECT *
FROM Member m LEFT OUTER JOIN Type t ON m.MemberType = t.Type;
你可能会说:“如果所有的会员在 MemberType 中都有值(它们本来就应该有值),那我们就不需要外连接了”。对这个案例来说,这没有任何问题。但是请回忆一下我在第2章中提到过的“假设所有的字段都拥有其该拥有数据”注7。在其他情况下,通过连接过来的字段就非常可能为空。我们在稍后的章节中会看到这样的查询“列出所有会员和他们的教练(如果有教练的话)”。丢失了行是因为你该用外连接时用了一个内连接。这是一个非常常见,而且难以察觉的错误。
那右外连接(right outer jion)和全外连接( full outer joins)呢注8?左外连接和右外连接其实是一样的,只是取于连接语句中表的排序而已。尽管下面的 SQL 中的字段排列和之前的不一样,但依然会返回和 图3-14 中所示的的相同数据。
SELECT *
FROM Type t RIGHT OUTER JOIN Member m ON m.MemberType = t.Type;
我们只要简单地交换一下连接一句中表的排序,右表(Member)中那些字段些含有 null 值的行就会被检索出来。
全外连接的左右表中都会含有 null 值。这里展示全外连接的 SQL,结果如 图3-15 所示。
SELECT *
FROM Member m FULL OUTER JOIN Type t ON m.MemberType = t.Type;
图3-15Member和Type表的全外连接结果
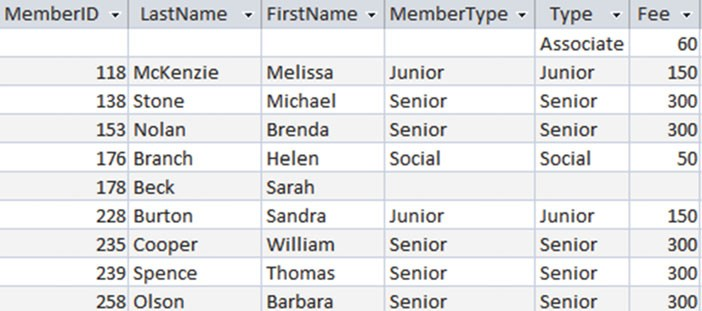
我们在 Type 表中有了关于 Sarah Beck 的填满了 null 值 的行。我们还有第一行,这行数据展示给了我们关于 Associate 的成员类型尽管在 Memeber 表中没有对应的行,但有 Assosicate 类型注9。在这一行中,Member 表中所有丢失的数据,都会被置换为 null 。
并不是所有的 SQL 都明确支持全外连接。Access 2013 就不支持。但是在 SQL 中总有一些其他的期待的方法,让查询得到想要的结果。在第七章中,我会告诉你通过 union 操作符通过左右连接去平替怎么去用全外连接(就像我在 图3-15 中所展示的那样)。
小结
两张表结合产生笛卡尔积。结果表中的所有字段可以和原始的两张表中的字段一一对应。原始的两张表的每行数据逐一结合,构成结果表的中所有行注10。展示了笛卡尔积的 SQL 则如下所示:
SELECT *
FROM <table1> CROSS JOIN <table2>;
结果方法式的内连接 SQL 则如下所示:
SELECT *
FROM <table1>,<table2>;
内连接从笛卡尔积开始,然后通过连接条件来确定要保留哪些来自原始表的行。
过程方法式内连接的 SQL 则如下所示:
SELECT *
FROM <table1> INNER JOIN <table2>
ON <join condition>;
结果方法式带选择条件的内连接 SQL 则如下所示注11:
SELECT *...
FROM <table1>, <table2>
WHERE <join condition>;
如果某张表(或者两张表都)的字段在连接条件中里有 null 值,则这一行不会被内连接匹配出来。如果这行数据必须有,你可以使用外连接。
在左表的结合条件中保留了所有 null 值的外连接 SQL 则如下所示:
SELECT *
FROM <table1> LEFT OUTER JOIN <table2>
ON <join condition>;
注
注0. 原书注: International Organization for Standardization. Information technology — Database languages — SQL . ISO, Geneva, Switzerland, 1992. ISO/IEC 9075:1992 ↩
注1. 这些多加的功能,也就是所谓中的“方言” ↩
注2. 这里的原文还有一句话,个人感觉逻辑有些跳,而且前半句和后面又些重复,所以姑且删除了这一句。
原文:However, the second row, where the member types from each table match, is useful because it allows us to see what fee Melissa pays. ↩
注3. 这里的原话有些看不懂,特别是最后一个逗号后面的部分。姑且先这么翻译,给出原文供参考。
原文:The reason that the way we write our SQL statements often doesn’t affect the efficiency of a query is that SQL is fundamentally based on relational calculus, which describes the criteria the retrieved rows must meet. ↩
注4. 参考资料:https://www.w3resource.com/sql/joins/perform-an-equi-join.php
https://baike.baidu.com/item/equijoin/50991774 ↩
注5. 参考:https://baike.baidu.com/item/自然连接 ↩
注6. 这里原文是 has a null or empty value,为了简单起见,直接翻译为“空值”,
如果不影响理解,今后将不再对 null 和空值(empty value)的差异进行区分 ↩
注7. 这里有些看不懂,暂且这么翻译。原文:but remember my cautions in Chapter 2 about assuming that fields that should have data will have data ↩
注8. 这里的原文是“What about right and full outer joins?”从上下文来判断,应该是右外连接和全外连接,故此翻译 ↩
注9. 这句话实在没看懂,暂且这么翻译。原文:We also have the first row, which shows us the information about the Associate membership type even though there are no rows in the Member table with Associate as a member type. ↩
注10. 这里用文字表示比较难理解,用代数打个比方就是数学里做因式分解。假设:表1 里有 3 行数据,表2 里有 4 行数据。
则将:表1 里有 3 行数据表达为:表1=表1行1+表1行2+表1行;
表2 里有 4 行数据表达为:表2=表2行1+表2行2+表2行3+表2行4;
表1 和 表2 的笛卡尔积表达为:表1×表2
所以:表1×表2
=(表1行1+表1行2+表1行3)×(表2行1+表2行2+表2行3+表2行4)
=表1行1×表2行1+表1行1×表2行2+表1行1×表2行3+表1行1×表2行4+表1行2×表2行1+表1行2×表2行2+表1行2×表2行3+表1行2×表2行4+表1行3×表2行1+表1行3×表2行2+表1行3×表2行3+表1行3×表2行4 ↩
注11. 原文中没有“带选择条件的”这几个字,但个人认为,这里加一下会比较好,以区别上文没有选择条件的 SQL ↩